ROS Group 产品服务
Product Service 开源代码库
Github 官网
Official website 技术交流
Technological exchanges 激光雷达
LIDAR ROS教程
ROS Tourials 深度学习
Deep Learning 机器视觉
Computer Vision
走在地平线机器人之前的人工智能创业公司——深鉴科技
-

深鉴科技FPGA平台DPU产品开发板就在昨天(美国当地时间5月18日)举办的2016谷歌I/O 开发者大会上,在介绍完一系列应用及产品后,谷歌CEO桑达尔·皮查伊(Sundar Pichai)发布了专门为机器学习而打造的硬件“张量处理单元”( Tensor Processing Unit,TPU)。虽然皮查伊并未明确解释TPU是基于何种平台,但业内人士从已经公布的数据,比如散热器尺寸、开发周期、性能指标等推测,也能对TPU的技术原理略知一二了。可见,在服务器端使用专用硬件来支持深度学习相关应用已是大势所趋。
编者按:ICLR(the International Conference on Learning Representations)大会是近年来在深度学习领域影响力飙升的行业会议,旨在讨论如何更好的学习有意义、有价值的数据,从而应用于视觉、音频和自然语言处理等领域。大会联合主席为深度学习领军人物Yoshua Bengio和Yann LeCun。
在2016 年5月举办的ICLR大会上,有两篇论文获得了“2016年ICLR最佳论文”奖。一篇来自AlphaGo开发者谷歌DeepMind,另一篇则来自深鉴科技首席科学家韩松,他在论文中解释了如何利用“深度压缩”(Deep Compression)技术,将神经网络压缩数十倍而不影响准确度,从而降低计算复杂度和存储空间。
韩松所在的深鉴科技(Deephi Tech)成立于今年2月,专注于深度学习处理器与编译器技术,希望让每一台智能终端与云服务器都具有高性能、低功耗的深度学习计算能力。这家成立不久的科技初创公司目前已获得金沙江创投与高榕资本的天使轮融资。

深鉴科技创始团队与著名华裔物理学家张首晟的合影。左起为姚颂、韩松、张首晟、汪玉进入正题之前,首先需要说明一个基本概念:FPGA(现场可编程门阵列,Field-Programmable Gate Array)。简而言之,这是一种程序驱动逻辑器件,就像一个微处理器,其控制程序存储在内存中,加电后,程序自动装载到芯片执行(该解释来自于中国科协“科普中国”)。
相比CPU和GPU,FPGA凭借比特级细粒度定制的结构、流水线并行计算的能力和高效的能耗,在深度学习应用中展现出独特的优势,在大规模服务器部署或资源受限的嵌入式应用方面有巨大潜力。此外,FPGA架构灵活,使得研究者能够在诸如GPU的固定架构之外进行模型优化探究。
众所周知,在深度神经网络计算中运用CPU、GPU已不是什么新鲜事。虽然Xilinx公司早在1985年就推出了第一款FPGA产品XC2064,但该技术真正应用于深度神经网络还是近几年的事。英特尔167亿美元收购Altera,IBM与Xilinx的合作,都昭示着FPGA领域的变革,未来也将很快看到FPGA与个人应用和数据中心应用的整合。
目前的FPGA市场由Xilinx和Altera主导,两者共同占有85%的市场份额。此外,FPGA正迅速取代ASIC和应用专用标准产品(ASSP)来实现固定功能逻辑。 FPGA市场规模预计在2016年将达到100亿美元。
深鉴科技创始人兼CEO姚颂对DT君表示,现在有很多公司在做各种各样的算法,包括ADAS(高级驾驶辅助系统)或者机器人等应用,因为算法是最快的切入方式。但算法最终要落地,无论是在CPU上运行,还是在GPU上运行,都会受限于性能、功耗和成本等因素。深鉴科技的产品将以ASIC级别的功耗,来达到优于GPU的性能,可把它称作“深度学习处理单元”(Deep Processing Unit,DPU),而第一批产品,将会基于FPGA平台。
他同时指出,深鉴科技目前的开发板功耗在4瓦左右,能够做到比一个15至20瓦的GPU性能高出两倍。而为了让所有做算法的人能够更加便捷地使用他们的产品,只有芯片肯定不行,所以他们也开发了自己的指令集和编译器。“相当于原来是先训练一个算法,然后再编译到CPU或GPU上运行,现在你也可以通过我们的编译器,把训练好的算法编译到DPU就可以直接运行了,在同样的开发周期内,获得相对于GPU一个数量级的能效提升。”
专访深鉴科技创始人兼CEO姚颂,这也是该公司第一次公开接受专访,全文如下,由“DeepTech深科技”编辑整理。

深鉴科技FPGA平台DPU产品开发板Q:DPU作为一个你们提出的新概念,其被认可程度如何?
姚颂:学术方面,ICLR 2016评选了两篇最佳论文,一篇是我们的《深度压缩:通过剪枝、受训量化和霍夫曼编码压缩深度神经网络》(Deep Compression: Compressing Deep Neural Networks With Pruning,Trained Quantization And Huffman Coding)。另一篇是谷歌DeepMind的《神经编程解释器》(Neural Programmer-Interpreters)。作为一个初创公司能拿到这个奖,对我们的激励是非常大的。我们的一系列论文也发表在NIPS 2015,FPGA 2016,ISCA 2016,这样一些在机器学习、计算机体系结构领域的最顶级会议上。
产业方面,今年二月份我们与全球最大的FPGA芯片制造商赛灵思(Xilinx)进行了交流,也与其他专注深度学习系统的硅谷公司进行了技术上的对比。之后,在OpenPOWER2016峰会中,赛灵思在讲到未来使用FPGA作为神经网络处理器加速标准时,所用的到的技术方面的PPT都是直接引用我们的公司的核心技术PPT,包括压缩以及卷积神经网络的硬件结构等。
相较于学术界的肯定,能被世界上最大的FPGA厂商认可并推广,更是一件令人振奋的事情。公司和清华的一篇合作论文也被半导体工业界的顶级会议Hot Chips 2016录用。
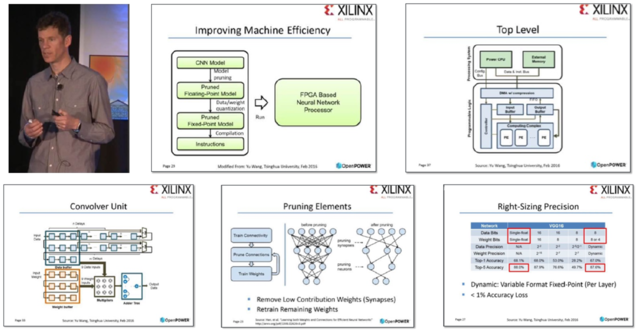
赛灵思 CTO 办公室的杰出工程师 Ralph Wittig 在 2016 年OpenPOWER峰会上的演讲Q:以前我们也有很多算法,但都是针对CPU和GPU,为什么深度学习出现后,你们会想到提出DPU这个新概念?
姚颂:首先是因为深度学习算法可以实用了,如果这个算法之前的精确度不足以实用,那么也没有必要专门开发DPU。另外,我们能够通过一个通用性的处理器来支持它,因为通用的神经网络基本上就是卷积层、非线性层、池化层,哪怕网络结构不同,最底层也还是这些基本单元。那么,一个支持这些底层操作的较为通用的处理器单元是可以满足这种要求的。
好比最开始我们需要运行一些程序,所以需要CPU;后来大家开始玩游戏,发现CPU满足不了3D渲染的需要,所以又加入了GPU。但如果深度学习技术像图形显示一样成为主流,大家都要具备智能计算的能力,将有一款专门的产品来替代,这是毫无疑问的。
Q:目前产品与主流CPU、GPU相比,具体性能表现如何?
姚颂:深度学习算法分为训练(Training)和应用(Inference)两部分。GPU平台并行度非常之高,在算法训练上非常高效,但在应用时,一次性只能对于一张输入图像进行处理,并行度的优势就不能完全发挥出来了。DPU只用于应用,也就是Inference阶段。目前基于FPGA的DPU产品可以实现相对于GPU有1个数量级的能效提升。
如在服务器端,我们基于FPGA的DPU板卡能够做到以更低的成本、低80%的功耗,实现多线程神经网络计算任务延迟降低数倍。而且兼容现有服务器与机房,可以实现即插即用。嵌入式端,DPU系统同样可以在降低80%功耗的情况下取得比GPU更好的性能。
而且从产品开发周期、迭代速度、生产成本、利用率方面来看,DPU产品虽然依托于FPGA平台,但是利用抽象出了指令集与编译器,可以快速开发、快速迭代,与专用的FPGA加速器产品相比,也具有非常明显的优势。
Q:DPU的瓶颈在哪里?
姚颂:DPU专门针对于深度学习算法设计,其应用范围只能是深度学习算法,而不像CPU与GPU那样通用。因此,在一些应用场景中,需要以DPU为核心,辅之以非机器学习或者非深度学习的方式相结合来打造完整系统。以手势检测为例,手的检测任务可以DPU运行深度学习算法来检测,但检测之后,判断手势速度我们会依赖摄像头和物体之间的几何关系求得,这一步就需要依赖于传统的方法了。当然,能否让用户用得习惯也是需要努力突破的地方,所以我们在一键生成指令上进行了很大的努力。
Q: FPGA平台的最大好处是什么?
姚颂:FPGA平台自身有三大优势:
首先是可编程,深度学习算法还未完全稳定,若深度学习算法发生大的变化,需要调整DPU架构,能够更新FPGA所搭载的DPU,适应最新的变化;
第二是高性能、低功耗。一方面,FPGA上可以进行比特级的细粒度优化,同时有十万级甚至更多执行单元并行处理,通过定制体系结构避免了通用处理器的冗余周期;另一方面,FPGA结构非常规整,相比于ASIC芯片可以享受最新的集成电路制造工艺带来的性能和功耗优势;
最后是高可靠性。FPGA有工业级与军工级芯片,都经过极低温与极高温下计算的苛刻测试,可以在各种环境下长时间稳定工作。
Q:深鉴科技开发的神经网络系统技术与全球比较知名的,如高通的Zeroth和IBM的TrueNorth相比,有什么特点?
姚颂:概念上和做法上都完全不一样。Zeroth和TrueNorth都是SNN,即Spiking Neural Networks,而现在实用的都是“卷积神经网络”( Convolutional Neural Networks,CNN),或者“深度神经网络”(Deep Neural Networks,DNN),在神经网络上有本质的区别。著名的AlphaGo即使用CNN来对场上局面进行分析。
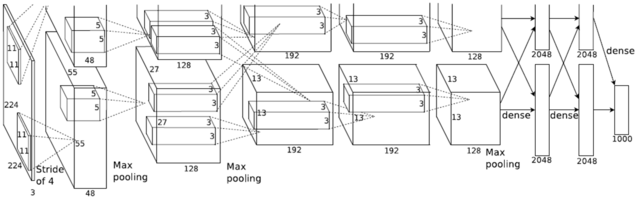
最经典的卷积神经网络(CNN)AlexNet结构示意图
Q:CNN和SNN的本质区别是什么?两者又有何优劣?
姚颂:CNN的神经元向后传递一个数值,下一层直接依赖于上一层输出的数值进行计算;SNN的神经元向后传播一个脉冲序列,不是单个数值。举一个简单的例子,CNN里面每个数都可以是一个16比特的数,SNN用16个时钟周期发16个脉冲来表示这个数。
CNN本质是生物启发的计算模型,并非是脑科学的模型。而SNN更好的模拟了人的神经网络,更加的“类脑”,有更强的生物学基础,可能具有非常大的潜力。但是在目前,CNN的训练手段比较成熟,在实际的问题上可以达到很高的精确度,而SNN的训练方法不成熟,也因此暂时应用于大规模的识别问题还比较困难。
Q:深鉴科技目前做出的产品主要在致力于解决哪些问题?
姚颂:我们主要解决了以下几个方面的难点:首先是分析方面,研究与分析深度学习算法的计算与存储上的特征(Pattern)。
其次是设计方面,利用这些深度学习算法的特征,设计针对于神经网络的压缩方法、设计DPU体系结构、并且设计对应指令集,使得DPU能够支持各类深度学习算法。
第三是应用方面,打通从算法到硬件的全流程,用软硬件协同设计达到最好效果,并且开发好用的压缩编译工具,让所有人都能够方便的使用DPU产品。
最后是协同优化与迭代,针对实际应用的算法模型,进行DPU体系结构的评估,发现算法中不适合加速部分,再对于算法与体系结构进行优化或调整,使得应用中全系统性能进一步提升。
Q:目前你们的产品所做的计算都是基于本地的么?
姚颂:对于嵌入式端,目前在无人机,以及ADAS上的应用是不能依赖于网络的,因为对于延迟的要求非常的高。现在要么是CPU,要么是GPU,前者计算能力不够,后者功耗太高。那么我们和很多公司讨论的结果是FPGA是一个很好的方向。而云端的计算平台,也是DPU产品应用的很好场景。
Q:具体技术方面是否方便简要解释一下?
姚颂:“深度学习”这个概念大家进来听得耳朵都快起茧子了,它带来的好处咱们就不再赘述了。深度学习算法特点与传统计算有一个最大的区别,就是大规模数据复用。举个例子:在传统计算中,我们要计算A+B=C,会分别读取A、读取B,计算一次,得出C,然后A和B就可以放弃不用了,之后的计算用C就可以了。
神经网络就不是这样,比如在卷积神经网络中,一个卷积核要与特征图(Feature Map)进行多次卷积运算,是一种非常频繁反复的运算。每读取一张图,需要运算很多次,每读取一个卷积核,需要跟很多特征图发生多次卷积运算。
这种大规模重复运算中,如果每次都去读取数据会非常不高效,这也是为什么CPU和GPU不能高效运行深度学习算法的原因。CPU是读取数据,计算完毕后再写回去,而且由于本身计算单元较少,其性能就会被局限;GPU与CPU相比,拥有更多的ALU(算术逻辑单元),CPU的ALU比较少,而GPU则ALU非常多,比如Nvidia TK1就拥有192个核。但GPU上ALU附近的存储还是不够大,所以也摆脱不了读数-计算-写回这个过程,也导致了能耗一直下不去。
我们认为针对深度学习计算中的大规模频繁复用,应该有一种专用的内存结构,所以我们就设计了DPU。最早从2013年就开始做了,到2015年中,我们做出了学术版的DPU,从那时起,就一直在往产品成熟化的方向做。
Q:DPU的功耗、可靠性和兼容性怎么样?
姚颂:基于FPGA平台的DPU已经能够相对于GPU取得约一个数量级的更高的能效(Performance Per Watt),在DPU芯片制造后,能效指标能比现有FPGA平台产品再提升至少20倍。
可靠性上,我们的DPU已经经过长期测试,目前已经可以稳定运行,并且在超低温、超高温稳定工作,但是仍然需要更多的算法进行测试,来保证更高的可靠性。
兼容性上,深度学习算法尽管可以有各种各样的网络结构,但底层的运算都是一致的,包含卷积、全连接、非线性、池化等,因此该指令集兼容所有通用的深度学习算法。
Q:对于这种新的架构设计,用户端在转换平台时会不会有什么不适应?
姚颂:完全不会,最简单的使用流程是这样的:用户之前在GPU上训练一个算法,我们完全不干涉,当你训练完一个算法,会生成一个算法模型文件,来对这个神经网络进行表述。这个算法模型文件会交给我们的编译器,通过压缩和编译,得出的指令可以直接下载到FPGA上,就可以直接快速运行了。
Q:目前深鉴科技在产品方面是否有具体的计划?会主要针对那些领域?
姚颂:目前我们在着手打造无人机和服务器两个行业的两款核心产品。这两款产品不是小规模的概念性产品,而是可以大规模上线的商业级产品。应用领域将分为终端和云端两类。就终端市场而言,可能针对的领域包括ADAS、无人机、机器人,以及安防监控;云端市场将核心针对大型互联网公司的语音识别和图像处理,从云计算角度讲,如果能用DPU替换原有的CPU、GPU服务器,性能提升与功耗下降带来的益处将是巨大的。
Q:深鉴科技未来会侧重硬件开发还是提供解决方案?
姚颂:我们定位在深度学习平台公司,公司将以DPU为核心打造解决方案,不仅仅是提供芯片,而是提供行业内的整体的接口和SDK,方便所有人使用。我们的目标是不仅打造最好的深度学习处理器技术,也要打造最好用的解决方案和最高效的整体系统。
Q:国内外目前在做类似DPU概念和产品的比较优秀的团队还有哪些?
姚颂:国内目前有中科院陈云霁与陈天石老师,他们的“寒武纪”芯片设计也在一系列国际顶级会议发表。前百度深度学习研究院创始人余凯老师创办的地平线机器人科技,以及比特大陆、云天励飞等公司也在做积极的尝试。整体人工智能硬件的市场还在培育,我们也是希望大家一起让这个方向成为主流。
本文转自http://mittr.baijia.baidu.com/article/462202