ROS Group 产品服务
Product Service 开源代码库
Github 官网
Official website 技术交流
Technological exchanges 激光雷达
LIDAR ROS教程
ROS Tourials 深度学习
Deep Learning 机器视觉
Computer Vision
rk3588使用npu加速运行whisper语音识别模型
-
rk3588运行whisper模型有三种方法:1.使用纯cpu运行原始pytorch模型;2.将whisper模型转成onnx各式,再转成rknn格式使用npu运行;3.利用npu提供的矩阵运算功能,结合cpu一起运行原始pytorch模型。方法1做不到实时,方法2有rockchip官方仓库。方法3是这篇教程介绍的,方法3比方法2更快,同时功能更完整,比如tiny和small模型都可以运行。
我们在https://github.com/usefulsensors/useful-transformers基础上,通过修复bug,增加运行参数和prompt控制输出字体格式,实现了多语言模型的实时准确推理,whisper tiny和base模型rtf<0.1, small模型rtf<0.5。一、优化修改后的开源代码库
二、代码运行说明
通过
git clone克隆代码后,准备好 Python 环境,然后执行transcrible_wav.py完成语音识别。- 克隆源代码:
git clone http://git.bwbot.org/publish/useful-transformers.git- 准备python运行环境:
我们在 RK3588 上使用的是 Ubuntu22.04 Desktop,默认的 Python 版本是 3.10。为了避免破坏系统环境,我们使用virtualenv来配置需要的 Python 运行环境。
sudo apt install python3-virtualenv #进入上面git clone下来的文件夹根目录 cd useful-transformers #创建虚拟环境 virtualenv --system-site-packages -p /usr/bin/python3 venv #激活虚拟环境 source venv/bin/activate #开始在虚拟环境中安装pybind11 pip install -i https://mirror.baidu.com/pypi/simple pybind11 #在虚拟环境中编译安装useful-transformers包,注意指令中的文件路径要改成自己的实际路径 export pybind11_DIR=/home/xiaoqiang/npu/useful-transformers/venv/lib/python3.10/site-packages/pybind11/share/cmake/pybind11 ./venv/bin/pip install ../useful-transformers -i https://pypi.mirrors.ustc.edu.cn/simple3.环境配置完成,开始运行whisper:
taskset -c 4-7 ./venv/bin/python -m useful_transformers.transcribe_wav ./wav/chinese.wav tiny zh运行指令格式如下,modelname可以为tiny、base、small、tiny.en、base.en、small.en或者自己微调的模型。languge可以为en或zh,分别代表英文和中文。
taskset -c 4-7 python -m useful_transformers.transcribe_wav <wav_file> modelname languge自己微调的模型可以用torch_state_dict_to_npz.py 文件来转换。
三、运行结果
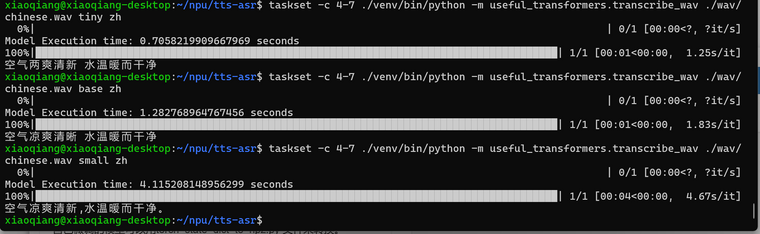
-
根据您提供的信息,您已经基于
useful-transformers项目做了很多优化工作,使得Whisper模型能够在Rockchip RK3588平台上实现更快的实时语音识别。以下是根据您的描述整理的步骤和说明:一、优化修改后的开源代码库
- 仓库地址:
二、代码运行说明
1. 克隆源代码
git clone http://git.bwbot.org/publish/useful-transformers.git2. 准备Python运行环境
在 RK3588 上使用的是 Ubuntu 22.04 Desktop,Python 版本是 3.10。为了避免破坏系统环境,使用
virtualenv配置需要的 Python 运行环境。sudo apt install python3-virtualenv cd useful-transformers virtualenv --system-site-packages -p /usr/bin/python3 venv source venv/bin/activate pip install -i https://mirror.baidu.com/pypi/simple pybind113. 编译安装
useful-transformers包export pybind11_DIR=/home/xiaoqiang/npu/useful-transformers/venv/lib/python3.10/site-packages/pybind11/share/cmake/pybind11 ./venv/bin/pip install ./useful-transformers -i https://pypi.mirrors.ustc.edu.cn/simple4. 运行Whisper
首先,确保已经安装了必要的依赖项,包括
torch,soundfile,numpy等。taskset -c 4-7 ./venv/bin/python -m useful_transformers.transcribe_wav ./wav/chinese.wav tiny zh这里的
-c 4-7是指定了CPU核心,用于并行运行任务。这有助于提高模型推理的速度。三、运行结果
运行上述命令后,
transcribe_wav.py脚本将读取指定的.wav文件,并使用指定的 Whiper 模型进行语音识别。模型大小和语言选项可以通过命令行参数指定。例如,对于中文的
tiny模型,可以这样运行:taskset -c 4-7 ./venv/bin/python -m useful_transformers.transcribe_wav ./wav/chinese.wav tiny zh对于自定义训练的模型,可以使用
torch_state_dict_to_npz.py脚本来转换模型权重。如果您希望进一步解释或提供运行结果示例,请告诉我。