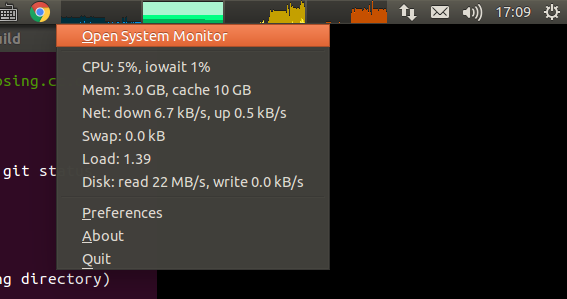
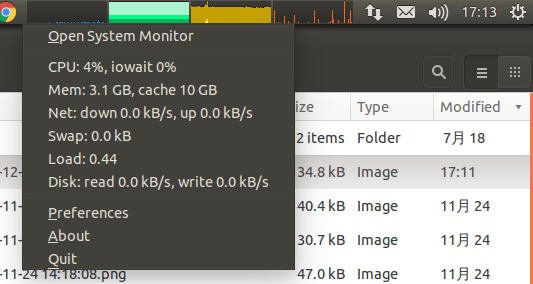
网上看到的,但是原链接
不过这里安装的是CUDA7.5,现在最新的是8.0。可以到官网进行下载,记住一定不要选择deb方式,会出问题。用run文件最好了。如果你已经安装过驱动了,一定在安装CUDA的时候选择不要安装驱动,否则系统的显卡驱动会出问题。
In this article, I will share some of my experience on installing NVIDIA driver and CUDA on Linux OS. Here I mainly use Ubuntu as example. Comments for CentOS/Fedora are also provided as much as I can.
Table of Contents
Install NVIDIA Graphics Driver via apt-get
Install NVIDIA Graphics Driver via runfile
Remove Previous Installations (Important)
Download the Driver
Install Dependencies
Creat Blacklist for Nouveau Driver
Stop lightdm/gdm/kdm
Excuting the Runfile
Check the Installation
Common Errors and Solutions
Additional Notes
Install CUDA
Install cuDNN
Table of contents generated with markdown-toc
Install NVIDIA Graphics Driver via apt-get
In Ubuntu systems, drivers for NVIDIA Graphics Cards are already provided in the official repository. Installation is as simple as one command.
For ubuntu 14.04.5 LTS, the latest version is 352. To install the driver, excute sudo apt-get nvidia-352 nvidia-modprobe, and then reboot the machine.
For ubuntu 16.04.1 LTS, the latest version is 361. To install the driver, excute sudo apt-get nvidia-361 nvidia-modprobe, and then reboot the machine.
The nvidia-modprobe utility is used to load NVIDIA kernel modules and create NVIDIA character device files automatically everytime your machine boots up.
It is recommended for new users to install the driver via this way because it is simple. However, it has some drawbacks:
The driver included in official Ubuntu repository is usually not the latest.
There would be some naming conflicts when other repositories (e.g. ones from CUDA) are added to the system.
One has to reinstall the driver after Linux kernel are updated.
Install NVIDIA Graphics Driver via runfile
For advanced user who wants to get the latest version of the driver, get rid of the reinstallation issue caused bby dkms, or using Linux distributions that do not have nvidia drivers provided in the repositories, installing from runfile is recommended.
Remove Previous Installations (Important)
One might have installed the driver via apt-get. So before reinstall the driver from runfile, uninstalling previous installations is required. Executing the following scripts carefully one by one.
sudo apt-get purge nvidia*
# Note this might remove your cuda installation as well
sudo apt-get autoremove
# Recommended if .deb files from NVIDIA were installed
# Change 1404 to the exact system version or use tab autocompletion
# After executing this file, /etc/apt/sources.list.d should contain no files related to nvidia or cuda
sudo dpkg -P cuda-repo-ubuntu1404
Download the Driver
The latest driver for NVIDIA products can always be fetched from NVIDIA’s official website. It is not necessary to select all terms carefully. The driver provided for the same Product Series and Operating System is generally the same. For example, in order to find a driver for a GTX TITAN X graphics card, selecting GeForce 900 Series in Product Series and Linux 64-bit in Operating System is enough.
If you want to down load the driver directly in a Linux shell, the script below would be useful.
cd ~
wget http://us.download.nvidia.com/XFree86/Linux-x86_64/367.57/NVIDIA-Linux-x86_64-367.57.run
Detailed installation instruction can be found in the download page via a README hyperlink in the ADDITIONAL INFORMATION tab. I have also summarized key steps below.
Install Dependencies
Software required for the runfile are officially listed here. But this page seems to be stale and not easy to follow.
For Ubuntu, installing the following dependencies is enough.
build-essential – For building the driver
gcc-multilib – For providing 32-bit support
dkms – For providing dkms support
(Optional) xorg and xorg-dev. On a workstation with GUI, this is require but usually have already been installed, because you have already got the graphic display. On headless servers without GUI, this is not a must.
As a summary, excuting sudo apt-get install build-essential gcc-multilib dkms to install all dependencies.
Required packages for CentOS are epel-release dkms libstdc++.i686. Execute yum install epel-release dkms libstdc++.i686.
Required packages for Fedora are dkms libstdc++.i686 kernel-devel. Execute dnf install dkms libstdc++.i686 kernel-devel.
Creat Blacklist for Nouveau Driver
Create a file at /etc/modprobe.d/blacklist-nouveau.conf with the following contents:
blacklist nouveau
options nouveau modeset=0
Note: It is also possible for the NVIDIA installation runfile to creat this blacklist file automatically. Excute the runfile and follow instructions when an error realted Nouveau appears.
Then,
for Ubuntu 14.04 LTS, reboot the computer;
for Ubuntu 16.04 LTS, excute sudo update-initramfs -u and reboot the computer;
for CentOS/Fedora, excute sudo dracut --force and reboot the computer.
Stop lightdm/gdm/kdm
After the computer is rebooted. We need to stop the desktop manager before excuting the runfile to install the driver. lightdm is the default desktop manager in Ubuntu. If GNOME or KDE desktop environment is used, installed desktop manager will then be gdm or kdm.
For Ubuntu 14.04 / 16.04, excuting sudo service lightdm stop (or use gdm or kdm instead of lightdm)
For Ubuntu 16.04 / Fedora / CentOS, excuting sudo systemctl stop lightdm (or use gdm or kdm instead of lightdm)
Excuting the Runfile
After above batch of preparition, we can eventually start excuting the runfile. So this is why I, from the very begining, recommend new users to install the driver via apt-get.
cd ~
chmod +x NVIDIA-Linux-x86_64-367.57.run
sudo ./NVIDIA-Linux-x86_64-367.57.run --dkms -s
Note:
option --dkms is used for register dkms module into the kernel so that update of the kernel will not require a reinstallation of the driver. This option should be turned on by default.
option -s is used for silent installation which should used for batch installation. For installation on a single computer, this option should be turned off for more installtion information.
option --no-opengl-files can also be added if non-NVIDIA (AMD or Intel) graphics are used for display while NVIDIA graphics are used for display.
The installer may prompt warning on a system without X.Org installed. It is safe to ignore that based on my experience.
WARNING: nvidia-installer was forced to guess the X library path ‘/usr/lib’ and X module path ‘/usr/lib/xorg/modules’; these paths were not queryable from the system. If X fails to find the NVIDIA X driver module, please install the pkg-config utility and the X.Org SDK/development package for your distribution and reinstall the driver.
Check the Installation
After a succesful installation, nvidia-smi command will report all your CUDA-capable devices in the system.
Common Errors and Solutions
ERROR: Unable to load the ‘nvidia-drm’ kernel module.
One probable reason is that the system is boot from UEFI but Secure Boot option is turned on in the BIOS setting. Turn it off and the problem will be solved.
Additional Notes
nvidia-smi -pm 1 can enable the persistent mode, which will save some time from loading the driver. It will have significant effect on machines with more than 4 GPUs.
nvidia-smi -e 0 can disable ECC on TESLA products, which will provide about 1/15 more video memory. Reboot is reqired for taking effect. nvidia-smi -e 1 can be used to enable ECC again.
nvidia-smi -pl can be used for increasing or decrasing the TDP limit of the GPU. Increasing will encourage higher GPU Boost frequency, but is somehow DANGEROUS and HARMFUL to the GPU. Decreasing will help to same some power, which is useful for machines that does not have enough power supply and will shutdown unintendedly when pull all GPU to their maximum load.
-i can be added after above commands to specify individual GPU.
These commands can be added to /etc/rc.local for excuting at system boot.
Install CUDA
Installing CUDA from runfile is much simpler and smoother than installing the NVIDIA driver. It just involves copying files to system directories and has nothing to do with the system kernel or online compilation. Removing CUDA is simply removing the installation directory. So I personally does not recommend adding NVIDIA’s repositories and install CUDA via apt-get or other package managers as it will not reduce the complexity of installation or uninstallation but increase the risk of messing up the configurations for repositories.
The CUDA runfile installer can be downloaded from NVIDIA’s websie. But what you download is a package the following three components:
an NVIDIA driver installer, but usually of stale version;
the actual CUDA installer;
the CUDA samples installer;
To extract above three components, one can execute the runfile installer with --extract option. Then, executing the second one will finish the CUDA installation. Installation of the samples are also recommended because useful tool such as deviceQuery and p2pBandwidthLatencyTest are provided.
Scripts for installing CUDA Toolkit are summarized below.
cd ~
wget http://developer.download.nvidia.com/compute/cuda/7.5/Prod/local_installers/cuda_7.5.18_linux.run
chmod +x cuda_7.5.18_linux.run
./cuda_7.5.18_linux.run --extract=$HOME
sudo ./cuda-linux64-rel-7.5.18-19867135.run
After the installation finishes, configure runtime library.
sudo bash -c "echo /usr/local/cuda/lib64/ > /etc/ld.so.conf.d/cuda.conf"
sudo ldconfig
It is also recommended for Ubuntu users to append string /usr/local/cuda/bin to system file /etc/environments so that nvcc will be included in $PATH. This will take effect after reboot.
Install cuDNN
The recommended way for installing cuDNN is to first copy the tgz file to /usr/local and then extract it, and then remove the tgz file if necessary. This method will preserve symbolic links. At last, execute sudo ldconfig to update the shared library cache.
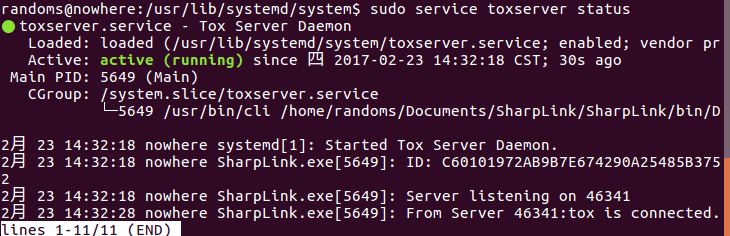
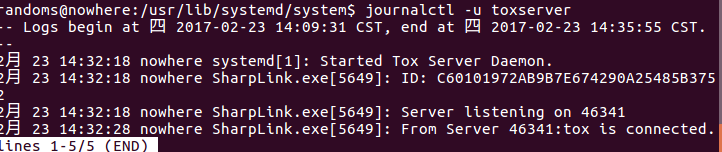
 。插上耳机后声音经常的是左边有声音右边没有这样子。在玩游戏的时候这样太不爽了。 而且像VNC这种远程软件是没有声音的,用起来也很不舒服。所以我很需要一个能够远程传输声音的软件。现在有了代码在
。插上耳机后声音经常的是左边有声音右边没有这样子。在玩游戏的时候这样太不爽了。 而且像VNC这种远程软件是没有声音的,用起来也很不舒服。所以我很需要一个能够远程传输声音的软件。现在有了代码在