ROS导航参数调整时一个很大的话题。具体参数调整可以参照这篇文章里面有很详细的介绍。
ROS交流群
ROS Group 产品服务
Product Service 开源代码库
Github 官网
Official website 技术交流
Technological exchanges 激光雷达
LIDAR ROS教程
ROS Tourials 深度学习
Deep Learning 机器视觉
Computer Vision
ROS Group 产品服务
Product Service 开源代码库
Github 官网
Official website 技术交流
Technological exchanges 激光雷达
LIDAR ROS教程
ROS Tourials 深度学习
Deep Learning 机器视觉
Computer Vision
weijiz 发布的帖子
-
小强出现异常时的调试发布在 技术交流
在使用过程中由于各种各样可能的原因会导致小强无法正常工作,这时候就需要我们进行调试,诊断出具体原因。
Q: 小车无法遥控
A: 运行bwcheck,根据输出进行判断。
首先查看是否检测到串口硬件。如果没有那么是不是udev规则有问题。重新插拔或换一个USB口看看是不是能够检测到硬件。
如果成功检测到硬件,检查底盘驱动程序是否正常运行,是否能够正常获取到小车电压。如果没有正常运行,执行sudo service startup restart重启服务程序。
Q: kinect 无法使用
A: 运行bwcheck,查看输出是否有kinect信息,如果提示没有找到kinect设备,重新插拔kinect USB接口。然后再次运行bwcheck,查看是否有对应设备。
如果有对应设备可以运行freenect-glview看看是否能够看到kinect图像。
如果有图像,那么运行对应的launch文件启动kinect就可以了。Q: 小车无法前进或无法后退
A: 有可能是小车的红外传感器触发了,检查周围是否有障碍物挡住了传感器。也可以通过发布消息禁用传感器,方法可以参照这里Q: 提示找不到rospack等常见ROS指令
A: 检查~/.bashrc文件,是否修改过其中的环境变量。如果是自己重新安装的系统,在安装时是否勾选了transfer user data的选项。Q: 在运行rviz和其他图形程序的时候提示 failed to open display
A: 你可能是在ssh的情况下运行这些程序的,这些程序都需要图形界面,但是ssh默认是无法提供图形界面的,所以会出错。
解决方法是在ssh的时候加上-X选项不如ssh -X xxx.xxx.xxx.xxx其中xxx.xxx.xxx.xxx是目标的ip地址。注意-X是大写的X。
Q: 通过设置ROS_MASTER_URI方式无法远程操作小强
A: 在进行远程遥控图传,激光雷达建图,amcl导航之类的操作时,经常需要设置ROS_MASTER_URI远程操作。
如果无法正常使用,首先检查ROS_MASTER_URI是否设置正确。然后检查本地的/etc/hosts和小强的/etc/hosts文件是否已经相互添加ip记录,以及ip记录是否正确。因为一般都是动态获取ip可能以前的已经不是现在的ip。
如果以上都没问题。是否本地使用的时虚拟机,网络是否设置成桥接。小强和本地是否能够相互ping通。如果仍然有问题可以试试关闭本地的防火墙。
-
小强中如何获得惯性导航数据发布在 技术交流
一般的ROS机器人都有惯性导航和全局导航(比如雷达,视觉)两种。小强也是如此。
惯性导航利用底盘编码器和陀螺仪进行定位。这样的定位方式是具有累计误差的,只能保证局部的准确性。
这样的惯性导航信息被称为小车的里程计(Odometry)。小强的Odom分布在/xqserial_server/Odom。可以通过rostopic echo 读取到。发布频率为50hz。读取里程计指令
rostopic echo /xqserial_server/Odom里程计的数据结构如下
std_msgs/Header header string child_frame_id geometry_msgs/PoseWithCovariance pose geometry_msgs/TwistWithCovariance twist其中header是数据头,包含时间戳和坐标系ID,pose为机器人里程计坐标,twist是当前小车的速度信息。
-
sophus编译错误的解决方法发布在 技术交流
error: optional in namespace Sophus does not name a template type在使用sophus库的时候可能会遇到如上的错误。这可能是由于系统中安装了ros自带的sohups库的原因。 运行
sudo apt-get remove ros-kinetic-sophus卸载系统自带的sophus库,再次编译即可。
-
ZED摄像头的使用发布在 技术交流
1. 安装CUDA
1.1 禁用原有的驱动
如果你之前安装了Nvidia的开源驱动,即通过apt-get 安装的驱动。则需要先把开源驱动禁用掉。
lsmod | grep nouveau #检测Nouveau是否开启,有输出则开启,无输出则为开启 #若Nouveau开启,执行以下命令 sudo gedit /etc/modprobe.d/blacklist-nouveau.conf #创建blacklist文件 # 在创建的文件中输入以下内容关闭掉Nouveau blacklist nouveau options nouveau modeset=0 # 更新list,使得更改生效 sudo update-initramfs -u然后再官网下载CUDA安装文件,推荐下载.run的文件
1.2 进入文本模式,禁用图像显示
下载完成后同时按下
Ctrl + Alt + F1进入文本模式,按照提示登入用户名密码。
然后执行下面指令关闭图形界面sudo service lightdm stop1.3 安装CUDA
执行
sudo sh cuda_9.2.148_396.37_linux.run根据安装过程的提示进行安装,一般默认就可以了。推荐安装上自带的驱动,防止自己安装驱动版本对不上。
1.4 设置环境变量
安装完成之后会提示设置环境变量,根据提示设置就可以了
在.bashrc文件中添加下面的内容export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib641.5 测试一下
bash nvcc -V正常应该会显示出CUDA的版本信息。
2. 下载安装SDK
从官方下载SDK
执行
chmod +x zed_sdk_file ./zed_sdk_file按照提示安装就可以了
3. 运行测试程序
cd /usr/local/zed/tools ./ZED\ Depth\ Viewer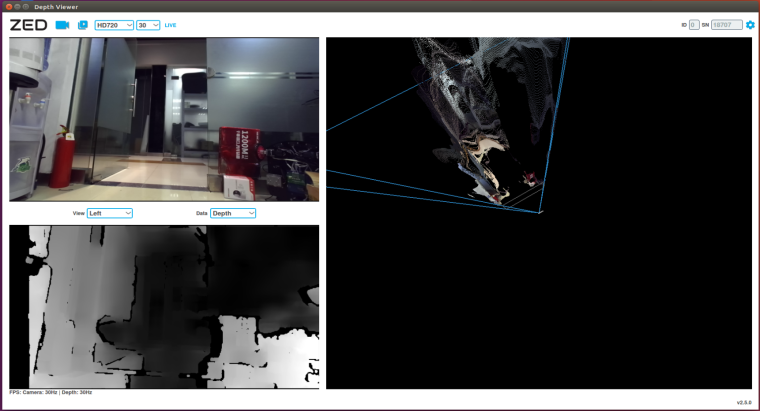
一切正常应该可以看到下图所示的画面。
4. 安装ROS驱动
cd [to your workspace]/src git clone https://github.com/stereolabs/zed-ros-wrapper cd .. catkin_make -DCATKIN_WHITELIST_PACKAGES="zed_wrapper"5. 测试ROS驱动
等待编译完成
roslaunch zed_display_rviz display.launch正常即可看到下面的显示了
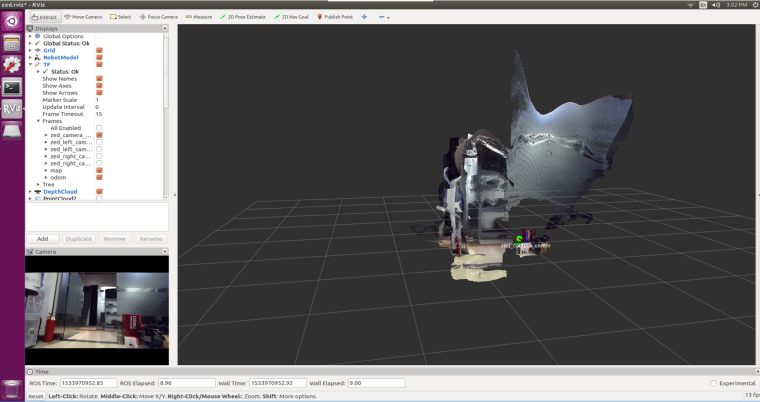
-
TX2刷机和使用常见问题发布在 技术交流
1. TX2介绍
Jetson TX2【1】是基于 NVIDIA Pascal
 架构的 AI 单模块超级计算机,性能强大(1 TFLOPS),外形小巧,节能高效(7.5W),非常适合机器人、无人机、智能摄像机和便携医疗设备等智能终端设备。
架构的 AI 单模块超级计算机,性能强大(1 TFLOPS),外形小巧,节能高效(7.5W),非常适合机器人、无人机、智能摄像机和便携医疗设备等智能终端设备。
Jatson TX2 与 TX1 相比,内存和 eMMC 提高了一倍,CUDA 架构升级为 Pascal,每瓦性能提高一倍,支持 Jetson TX1 模块的所有功能,支持更大、更深、更复杂的深度神经网络。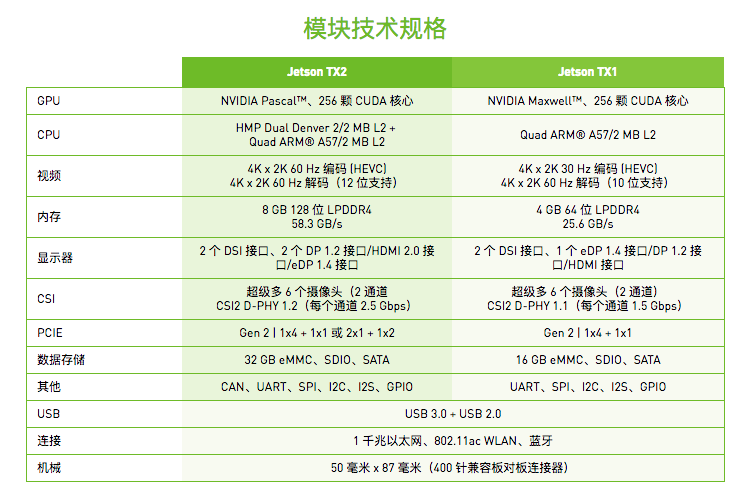
2. TX2刷机
系统要求
要给TX2刷机,需要一台装有Ubuntu 16.04系统的主机1. 下载安装jetpack软件包
官方下载地址 注意下载时需要注册成为Nvidia开发者
安装jetpack
chmod +x ./JetPack-L4T-3.1-linux-x64.run ./JetPack-L4T-3.1-linux-x64.run
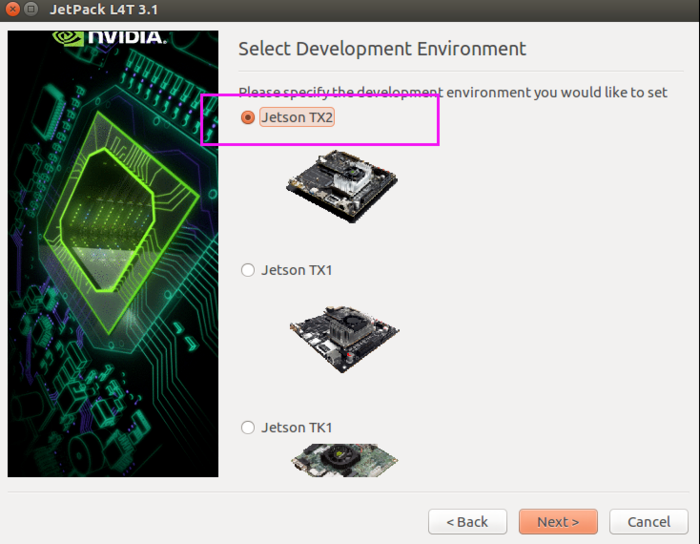
如果出现下图则需要通过设置环境变量,让程序使用单线程下载,然后再此启动程序
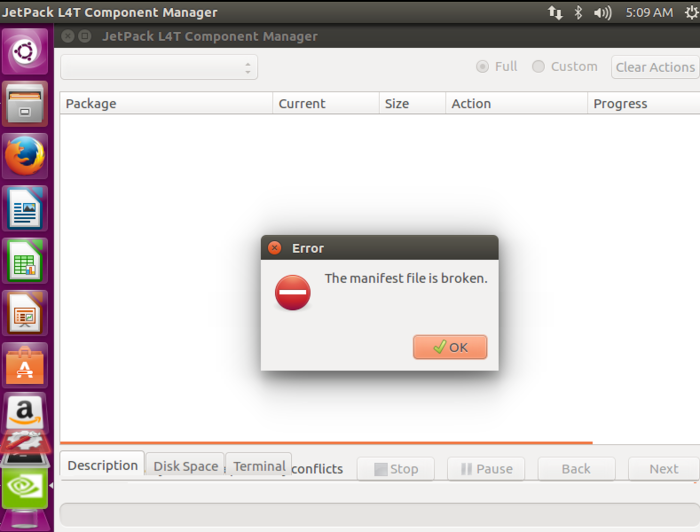
通过此指令设置环境变量
NV_DEVTOOLS_FORBID_MULTIPLE_DOWNLOAD_THREADS=1然后选择next
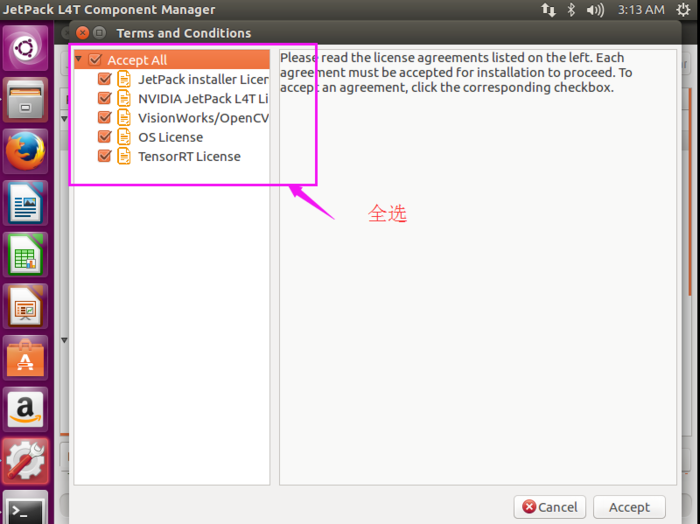
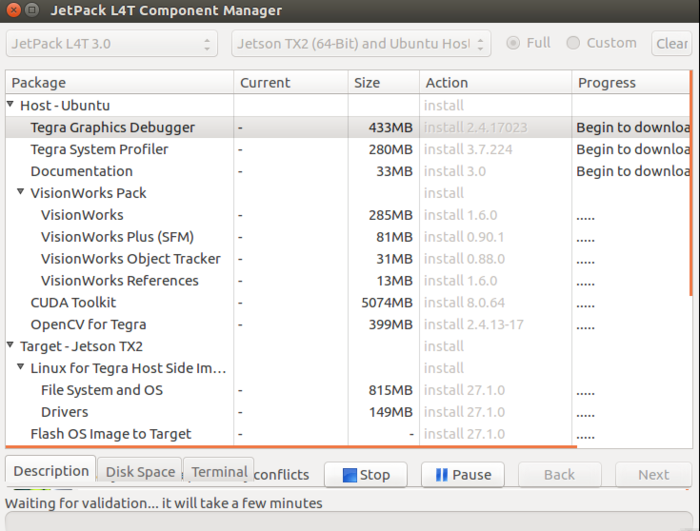
等待下载安装完成
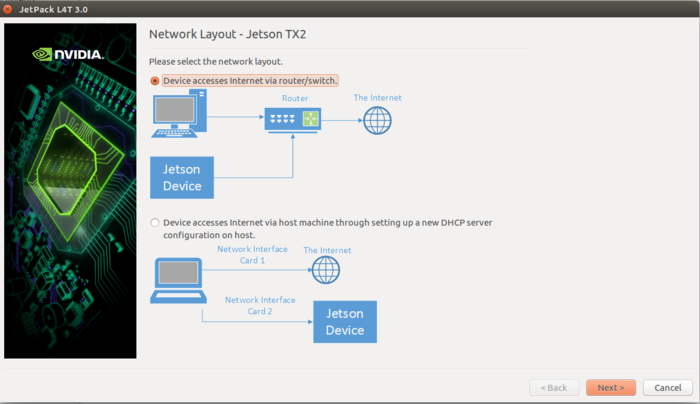
在出现此界面后保证给TX2连上网线,并且和自己的电脑在同一局域网内。
然后点击next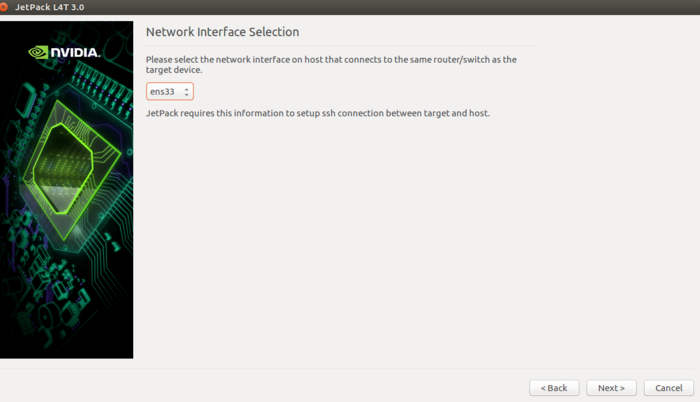
在此界面中选择正确的网卡(当前机器正在使用的有线网络)
一路Next 直到出现下图
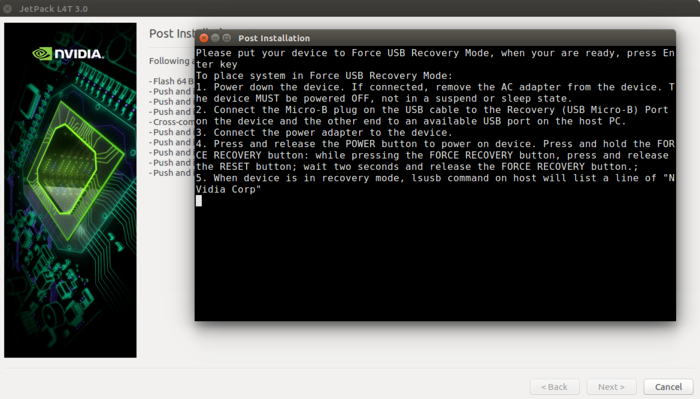
此窗口提示需要让TX2进入recovery模式
把通过USB线连接TX2和主机。然后给TX2重新插上电源。按下电源键(标有Power的按钮)后放开,之后按下Recovery按钮(标有REC的按钮)不放,同时按下复位键(标有RESET的按钮),可以看到指示灯闪了一下。说明已经进入recovery模式了。在主机上执行lsusb应该能够看到下面的输出
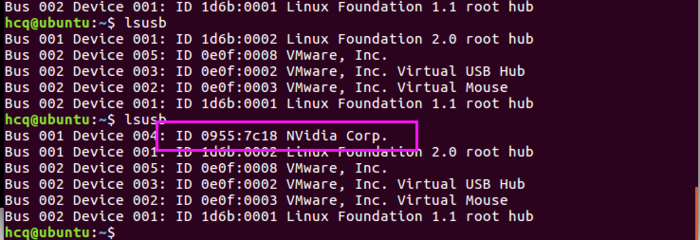
此时在刚才弹出的窗口中按回车键,刷机程序就开始执行了。
等待安装完成
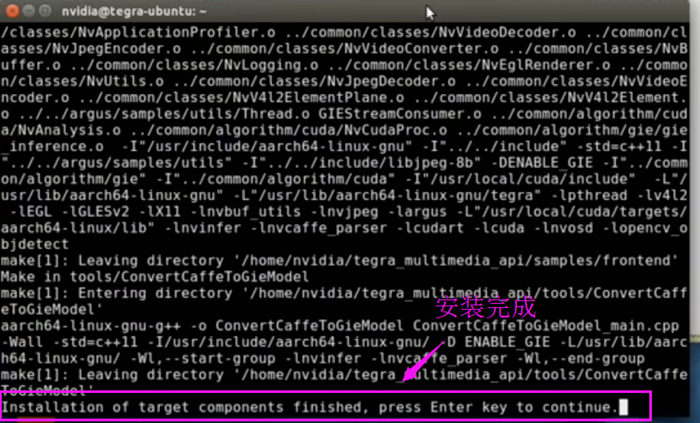
出现此窗口则说明已经安装完成
此时关闭窗口,然后重新开启TX2,就可以开始使用了。
3. TX2的使用
1. TX2的显示
TX2主板上提供了hdmi接口。如果有hdmi接口的显示器可以直接使用。如果没有hdmi接口的显示器可以使用vga转hdmi的转接头。但是转接头不一定好用,这涉及到显示驱动的问题。如果尝试了转接头仍然不好用,可以尝试使用vnc的方法。
在Ubuntu中使用VNC可以参照这一篇文章在路由器界面中可以看到TX2的ip,通过ssh进入tx2
然后按照上文的方法安装vnc安装完成后
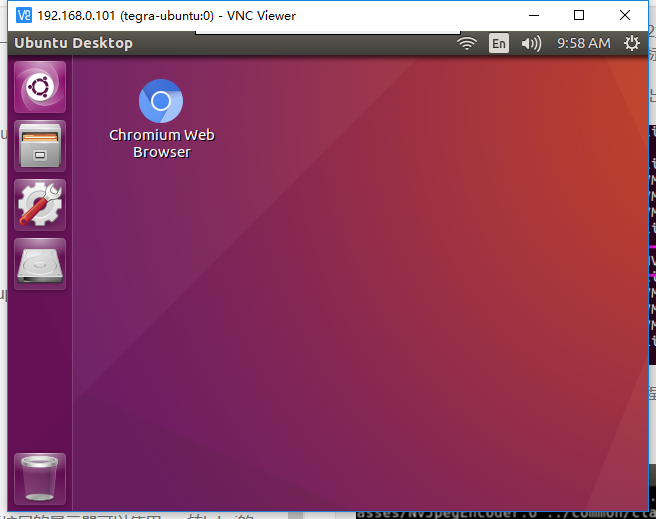
就可以使用了。这种方法也非常适合在移动平台上使用TX2时的远程调试
2. TX2的分区
TX2本身的硬盘空间只有32G,对于一些复杂应用可能是不够的。用户可以自己外接硬盘,硬盘接口和普通的笔记本接口一样。然后可以通过修改TX2的fstab来挂载自己的硬盘。
但是实际使用时发现,不能替换掉原系统的/usr分区。会出现各种各样的问题,比如wifi无法使用,软件源报错等等。建议挂在到/home上。
3. TX2的备份
执行下面的指令进行备份
sudo ./flash.sh -r -k APP -G backup.img jetson-tx2 mmcblk0p1注意备份时间会比较长,生成的文件也很大,有三十多G。其中backup.img 为备份文件的名字。
还原时先把备份文件复制到bootloader文件夹里面,替换掉原本的文件。
sudo cp backup.img.raw bootloader/system.img然后执行刷机指令
sudo ./flash.sh -r -k APP jetson-tx2 mmcblk0p14. TX2的模式
TX2默认处于低功耗模式可以执行下面的指令开启最大性能
sudo nvpmodel -m0 sudo ./jetson_clocks.sh4. TX2的坑
1. TX2会破环自己电脑的系统的软件源
在自己的电脑上安装jetpack之后,软件源会被程序修改,导致apt-get update 失败。这是由于jetpack给原系统添加了arm的软件源,而其中有些源会下载失败。解决方法时删去arm的软件源
sudo dpkg --remove-architecture arm642. 安装ROS
安装ROS和官方安装方法是完全一样的
5. TX2的相关资源
https://www.elinux.org/Jetson_TX2
提供了TX2相关的各种信息。
-
Ubuntu 更新时提示locale错误的解决方法发布在 技术交流
在更细系统是有时会出现下面的错误
perl: warning: Setting locale failed. perl: warning: Please check that your locale settings: LANGUAGE = (unset), LC_ALL = (unset), LC_PAPER = "zh_CN.UTF-8", LC_ADDRESS = "zh_CN.UTF-8", LC_MONETARY = "zh_CN.UTF-8", LC_NUMERIC = "zh_CN.UTF-8", LC_TELEPHONE = "zh_CN.UTF-8", LC_IDENTIFICATION = "zh_CN.UTF-8", LC_MEASUREMENT = "zh_CN.UTF-8", LC_CTYPE = "en_US.UTF-8", LC_TIME = "zh_CN.UTF-8", LC_NAME = "zh_CN.UTF-8", LANG = "en_US.UTF-8" are supported and installed on your system. perl: warning: Falling back to a fallback locale ("en_US.UTF-8").这是由于系统默认语言没有设置。可以执行下面的指令进行设置
sudo dpkg-reconfigure locales根据界面中的提示选择语言就可以了。
-
RE: 小强的stm32底板的串口接到windows平台上发布在 产品服务
通信协议可以看这里 https://doc.bwbot.org/books-online/xq-manual/topic/19.html
-
RE: ROS中c++编程问题发布在 技术交流
@rockyren dll是windows的链接库文件,现在ROS不支持windows。在linux上对应的文件是so文件。这个是可以通过修改CMakelists.txt文件进行添加的。
-
Ubuntu 18.04 failed to start user manager for uid错误的解决方法发布在 技术交流
简单说来就是显卡驱动的问题,进入recovery 模式然后重新安装显卡驱动就可以了。
-
物体识别:在深度学习时代的回顾发布在 机器视觉
从简单的图像分类到3D姿势估计,计算机视觉中不乏有趣的问题。 我们最感兴趣的问题之一就是物体识别。 像许多其他计算机视觉问题一样,现在仍然没有明显“最佳”的方法来解决问题,这意味着仍有很大的改进空间。 在进入物体识别之前,让我们快速了解该领域中最常见的问题。
物体检测与其他计算机视觉问题
分类
图片分类可能是计算机视觉中最着名的问题。 它包括将图像分类为许多不同类别中的一个。 学术界最常用的数据集之一是ImageNet,由数百万个分类图像组成。部分被用于每年的ImageNet大规模视觉识别挑战赛(ILSVRC)。 近年来,分类模型的表现已经超越了人类,并且这个问题已经被认为基本解决。 虽然图像分类存在很多挑战,但也很多关于如何解决这些挑战的文章。

定位
与分类类似,定位就是查找图像内单个对象的位置。

定位可用于许多有用的现实问题。 例如,智能裁剪(知道基于对象所在位置裁剪图像的位置),或者甚至是使用不同技术,进行进一步处理的常规对象提取。 它可以与分类相结合,不仅可以定位对象,还可以将其分类为许多可能的类别之一。
实例细分
从物体识别更进一步,我们不仅希望在图像中找到对象,而且还要找到每个检测到的对象的逐像素标记。 我们将此问题称为实例或对象分割。
物体识别
同时考虑定位和分类的问题,那么我们最终需要同时检测和分类多个对象。 物体识别是在图像上查找和分类可变数量的对象的问题。 重要的区别是“可变”部分。 与分类等问题相反,物体识别的输出长度可变,因为识别到的物体数量可能会因图像而异。 在这篇文章中,我们将详细介绍实际应用,作为机器学习问题的物体识别的主要问题是什么,以及在过去的几年中如何通过深度学习来解决它的方法。

物体检测的实际用途
尽管物体识别在某种程度上仍然是业界的新工具,但已经有许多有用且令人兴奋的应用程序使用它。
人脸识别
自2000年代中期以来,一些傻瓜相机开始具备检测面部的功能,以实现更高效的自动对焦。 虽然它是一种较窄类型的对象检测,但所使用的方法适用于其他类型的对象,我们稍后将对其进行描述。
计数
物体识别的一个简单但经常被忽略的用法是计数。 计算人,汽车,花朵甚至微生物的能力是对使用图像的不同类型系统广泛需要的现实世界需求。 最近,随着视频监控设备的不断涌现,使用计算机视觉将原始信息转化为结构化数据的需求比以往任何时候都要大。
可视化搜索引擎
最后,我们喜欢的一个用例是Pinterest的视觉搜索引擎。 他们使用对象检测作为工作流程的一部分来索引图像的不同部分。 这样,当搜索特定钱包时,您可以在不同的上下文中找到类似于您想要的钱包的实例。 这比仅仅找到类似的图像要强大得多,就像Google Image的反向搜索引擎一样。

航空影像分析
在廉价无人机和(接近)经济实惠的卫星发射时代,我们的世界从未有过如此多的数据。 已经有公司使用来自Planet和Descartes Labs等公司的卫星图像,应用物体检测来计算汽车,树木和船只。 这导致了一般民众也能访问到在以前是不可能的(或非常昂贵)高质量的数据。
一些公司正在使用无人机镜头对难以到达的地方(例如BetterView)进行自动检查,或使用物体识别进行通用分析(例如TensorFlight)。 除此之外,一些公司在不需要人为干预的情况下添加自动检测和问题定位。

物体检测存在的问题和挑战
让我们开始深入了解物体识别的主要问题。
可变数量的对象
我们已经提到了关于可变数量的对象的部分,但是我们省略了为什么它根本是一个问题。 在训练机器学习模型时,通常需要将数据表示为固定大小的向量。 由于事先不知道图像中的对象数量,因此我们不知道正确的输出数量。 因此,需要进行一些后处理,这增加了模型的复杂性。
历史上,使用基于滑动窗口的方法来处理可变数量的输出。通过为所有不同位置生成该窗口的固定大小的特征。 获得所有预测后,一些被丢弃,一些被合并以获得最终结果。
-
在小强上使用Yolo进行物体识别发布在 机器视觉
物体识别是指讲图片中的物体识别出来,包括物体的位置和类别。
以下面的图片为例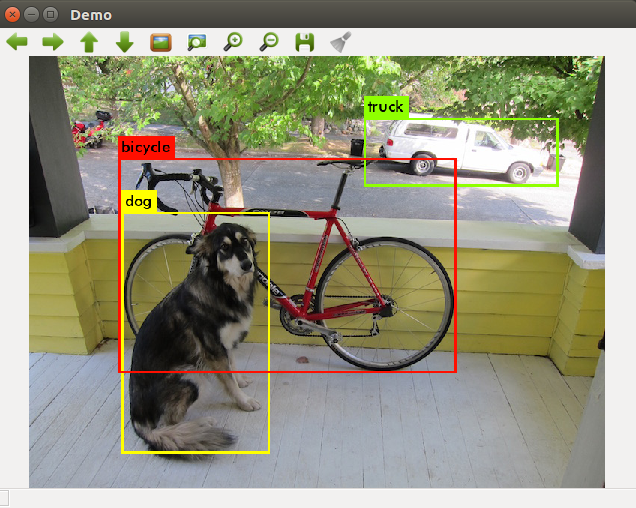
可以看出程序成功找出了图片中的自行车,狗和卡车。
Yolo是一个很高效的物体识别程序,在有Nvida GPU和CUDA的情况下可以做到实时处理。由于小强没有Nvidia GPU,只能采用CPU运行,速度会比较慢。下面是安装和使用方法。
下载和编译程序
cd [到你的工作空间]/src git clone --recursive https://github.com/BluewhaleRobot/darknet_ros cd .. catkin_make -DCMAKE_BUILD_TYPE=Release等待编译完成。注意编译过程中要有网络连接。程序会在编译的时候自动从网络下载yolo的训练模型数据。
参数配置
主要的参数位于ros.yaml
其中 camera_reading topic是图像的接收话题,小强上设置为/camera_node/image_raw就可以了。
默认启动程序后会有一个显示图像的窗口,如果不想打开可以设置 enable_opencv 为 false
默认Yolo的输出会在终端显示,可以通过设置enable_console_output false 禁用。运行程序
roslaunch darknet_ros yolo_v3.launch一切正常就可以看到输出的图像了

-
使用xiaoqiang_track进行人体跟随和追踪发布在 技术交流
xiaoqiang_track
xiaoqiang_track是一个利用摄像头捕捉的图像进行人体追踪的程序。它有比较好的稳定性,能够可靠的追踪目标。同时也具有比较好的扩展性。可以方便的对关键的追踪算法进行调整。在运动的控制上,使用了PID控制,可以通过调整参数适应不同的设备。
原理简介
通过人体识别算法获取到人体的上半身位置。获取成功后就把对应的位置信息传递给追踪程序。追踪程序进行目标追踪。运动控制程序根据当前的目标的位置计算运动控制量。
由于在追踪过程中可能会丢失,丢失的情况下就要再次使用人体识别程序的结果进行追踪程序的初始化。安装
以下安装方法只在ubuntu 16.04 kinetic版本测试过,如果需要在其他版本使用可能需要调整部分指令。
安装相关依赖程序
sudo apt-get install libjsoncpp-dev libcurl3 libcurl4-openssl-dev openssl安装body_pose人体识别程序
详细安装方法请参照 body_pose使用说明
可选程序
本程序有语音提示功能,如果想要这个功能可以安装xiaoqiang_tts软件包
安装源代码
cd 到你的工作空间/src git clone https://github.com/bluewhalerobot/xiaoqiang_track cd 到你的工作空间 catkin_make运行要求
由于使用的是摄像头追踪方法,所以首先要有一个摄像头设备。同时此设备能够通过ROS的软件包把图像信息通过topic形式发送出来。
对于小强用户,下面的运行指令直接执行就可以。对于其他用户请修改launch文件中的usb_cam节点。替换成自己的摄像头节点。由于要进行人体识别,摄像头的视野范围也很重要。要能保证在合适的追踪距离下摄像头能够比较完整的看到追踪目标。
对于小强用户,把摄像头固定在二层上,同时有一定的仰角就可以了。
注意图像的分辨率是640x480运行
小强用户请先关闭startup服务
sudo service startup stop启动roscore
roscore启动底盘驱动程序
# 这里是小强的驱动程序,如果不是小强,需要换成自己的 roslaunch xqserial_server xqserial.launch开始运行追踪程序
# 使用body_pose人体识别程序进行人体识别 roslaunch xiaoqiang_track track_body.launch # 或者使用百度的人体识别服务 roslaunch xiaoqiang_track track_baidu.launch此时站在摄像头前面,等待初始化完成就可以开始追踪了。注意在转弯的时候适当放慢速度。小车跟不上的话可能会导致追踪丢失。
如果想要实时的看到处理结果可以订阅/xiaoqiang_track/processed_image图像话题。其中的方框即为实时的追踪结果。

参数说明
详细参数请参照launch文件中的注释。
-
在ROS中使用Python3发布在 技术交流
当前ROS是只支持Python2.7的。Python3的支持在ROS的计划中,详细的可以看这里。简单说来就是要到2020年ROS的N版本才能完全支持Python3。
首先要了解为什么ROS不能支持Python3.对于纯的Python代码同时支持Python3和Python2.7是比较容易的,基本上ROS的代码也都是支持的。问题在于包含了C++或者C的那部分Python代码。Python2.7和Python3的c module代码相差很大。一次只能编译其中的一种版本。而且很多module没有做好Python3的支持。在Python3环境下也无法编译。这就是ROS无法支持Python3的原因。目前ROS的核心包都是支持用Python3从源码编译的。但是官方并没有发布Python3的软件包。所以想要使用的话要自己编译。下面介绍两种使用Python3的方法。
- 使用Python3和Python2.7的混合环境
原理:使用virtualenv创建一个Python3的环境。然后在这个环境中编译安装自己需要的软件包。在引用软件包的时候,如果没有对应的Python3的软件包,会自动的去Python2.7的环境里面找。这样很多软件包都是可以通用的。当然对于没有做好Python3支持的软件包也是没法用的。
下面以geometry2为例子
sudo apt-get install python3-dev mkdir catkin_ws # 创建工作空间 cd catkin_ws mkdir src cd src # 下载geometry和geometry2的源代码 git clone https://github.com/ros/geometry git clone https://github.com/ros/geometry2 cd .. # 创建虚拟环境 virtualenv -p /usr/bin/python3 venv source venv/bin/activate pip install catkin_pkg pyyaml empy rospkg numpy catkin_make source devel/setup.bash这样就能够成功在Python3下使用tf的相关函数了。
运行Python3程序
Python 3.5.2 (default, Nov 23 2017, 16:37:01) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tf >>> tf.__file__ '/home/xiaoqiang/Desktop/catkin_ws/devel/lib/python3/dist-packages/tf/__init__.py' >>> import tf2_py >>> tf2_py.__file__ '/home/xiaoqiang/Desktop/catkin_ws/devel/lib/python3/dist-packages/tf2_py/__init__.py' >>>可以看到我们的tf已经是在Python3的路径下了。
- 从源码安装ROS
首先把ROS都卸载干净
sudo apt-get purge ros-* sudo apt-get autoremove创建ROS工作空间
mkdir ros创建Python3环境
cd ros # 把系统默认Python替换成Python3 sudo rm -rf /usr/bin/python sudo ln -s /usr/bin/python3.5 /usr/bin/python sudo apt install python3-pip安装ros的编译基础软件包
sudo apt-get install python3-rosdep python3-rosinstall-generator python3-wstool python3-rosinstall build-essential sudo pip3 install catkin_pkg开始下载相关软件包
rosinstall_generator desktop --rosdistro kinetic --deps --tar > kinetic-desktop.rosinstall wstool init -j8 src kinetic-desktop.rosinstall # 如果上一步有失败的,执行 wstool update -j 4 -t src这里安装的是kinetic版本。其他版本需要调整对应的参数。
安装软件包依赖
rosdep install --from-paths src --ignore-src --rosdistro kinetic -y sudo apt-get install libtbb-dev python3-pyqt5 sudo pip3 install empy numpy defusedxml netifaces # 修复 16.04 libboost_python3找不到的问题 sudo ln -s /usr/lib/x86_64-linux-gnu/libboost_python-py35.so /usr/lib/x86_64-linux-gnu/libboost_python3.so编译工作空间
./src/catkin/bin/catkin_make_isolated --install -DCMAKE_BUILD_TYPE=Release如果这个过程中编译有错误,一般是缺少软件包之类的。需要下载安装对应的软件包然后再次编译。直到全部编译成功。
添加环境变量
在~/.bashrc里面添加
source /home/xiaoqiang/Documents/ros/install_isolated/setup.bash这里是小强的路径,你要根据自己的工作空间的位置进行修改。
之后再重新打开一个终端就可以了。
In [2]: import tf2_ros In [3]: tf2_ros.__file__ Out[3]: '/home/xiaoqiang/Documents/ros/install_isolated/lib/python3/dist-packages/tf2_ros/__init__.py' In [4]:可以看到现在的ROS使用的Python已经是Python3了。
总结虽然以上两种方法都可以使用Python3,但是推荐还是使用第一种方法。第二种方法使用起来比较费事,而且一旦使用了Python3就没办法使用Pyhon2.7了。有些软件包并没有做好Pyhon3的支持。这样会在使用中产生不少问题。
- 使用Python3和Python2.7的混合环境
-
使用python代码启动launch文件发布在 技术交流
在开发中我们经常会遇到使用python代码启动launch文件这样的问题。一般的做法是使用subprocess调用roslaunch。但是这种方法使用起来并不方便。要涉及到自己去控制进程的状态。由于roslaunch实际上是用python实现的。使用python调用launch文件实际上有更简单的方法。
import roslaunch uuid = roslaunch.rlutil.get_or_generate_uuid(None, False) roslaunch.configure_logging(uuid) tracking_launch = roslaunch.parent.ROSLaunchParent( uuid, ["/home/xiaoqiang/Documents/ros/src/xiaoqiang_track/launch/track_body.launch"]) tracking_launch.start()这样就成功启动了一个launch文件。把uuid后面的路径换成自己的launch文件路径就可以了。
而且我们可以通过roslaunch直接关闭launch文件启动的节点。
tracking_launch.shutdown() # tracking_launch 即是上面通过roslaunch获取到的变量这样使用起来就很方便了。
-
在小强上使用body_pose进行人体识别发布在 技术交流
body_pose 是一个人体姿态识别的软件包。这个软件包可以从图片中识别出人体的耳朵,眼睛,鼻子,四肢的共17个特征点。其实现是通过深度学习网络利用tensorflow框架。此软件还支持多人同时识别。

安装
- 安装tensorflow
由于小强上面没有Nvidia显卡, 所以我们安装CPU版本的Tensorflow。小强的CPU支持一些高效的指令集,默认的Tensorflow为了能够在更多平台上运行,没有使用这些指令集。所以性能实际上没有发挥到最高。我们可以安装开启了这些优化指令的版本。
sudo pip install --ignore-installed --upgrade "https://github.com/lakshayg/tensorflow-build/raw/master/tensorflow-1.4.0-cp27-cp27mu-linux_x86_64.whl"- 安装软件包相关依赖
sudo pip install scipy scikit-image matplotlib pyyaml easydict cython munkres==1.0.12- 下载相关模型
# 单人模型 cd src/models/mpii ./download_models.sh $ cd - # 多人模型 ./compile.sh cd models/coco ./download_models.sh cd -运行
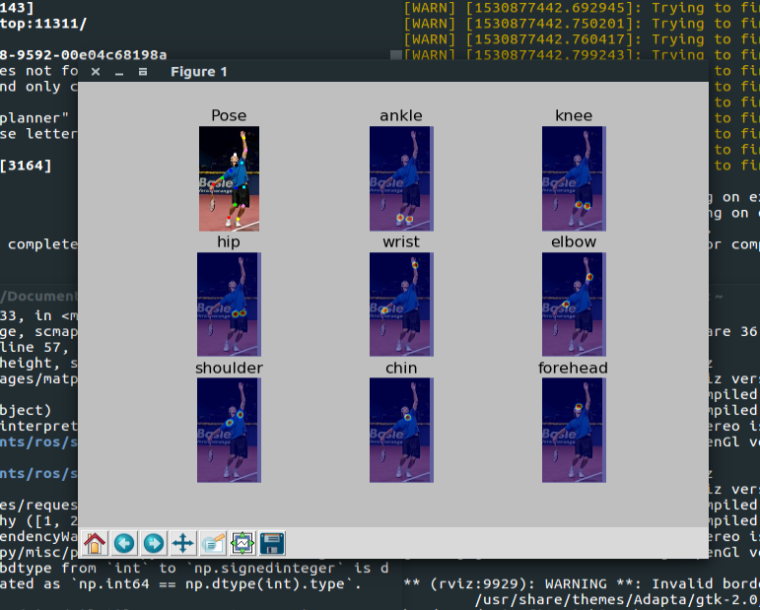
- 运行单人识别测试程序
# 在src文件夹内运行 TF_CUDNN_USE_AUTOTUNE=0 python demo/singleperson.py运行成功后可以看到下图
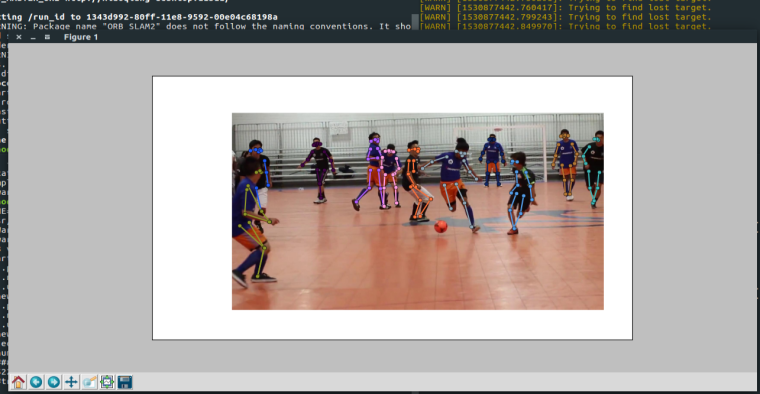
- 运行多人识别的例子
TF_CUDNN_USE_AUTOTUNE=0 python demo/demo_multiperson.py成功运行后显示下面的图像
- 运行ROS服务
roslaunch body_pose body_pose_test.launch这个launch文件在小强上可以直接运行。但是如果不是在小强上你需要把usb_cam的节点换成自己的摄像头节点。
服务启动成功后会自动的识别摄像头中的图像。处理的结果会显示在/body_pose_tester/processed_imagetopic 里面。可以利用摄像头显示处理结果。rosrun image_view image_view image:=/body_pose_tester/processed_image可以看到图中标了一些圆圈。这些都是被识别出的人体特征位置。

在自己的程序中使用此服务
可以在自己的launch文件中添加这样的内容来启动节点
<node name="body_pose" pkg="body_pose" type="body_pose_node.py"> <param name="process_width" value="200" /> <param name="process_height" value="150" /> <param name="conf_min_count" value="3" /> </node>参数说明
process_width 内部处理宽度,process_height内部处理高度。可能采集的图片很大,这样处理起来非常费时间。可以通过这两个参数对图片进行压缩以提高处理速度。
conf_min_count最小可接受点数。如果在一个人上识别出的特征点小于这个值,则认为这个识别对象并不是人。发布的服务
服务默认发布在~get_body_pose可以类型为BodyPose.srv。详细的使用方法可以参照 body_pose_test_node.py 文件。
- 安装tensorflow